第八章 濾波與卷積 | Filtering and Convolution
在這章我會介紹訊號處理相關領域最重要最有用的觀念之一,卷積理論。但在我們了解卷積理論之前,我們要先懂卷積。我會先從簡單的範例開始,也就是平滑化,以它為出發點。這章的程式碼在 chap08.ipynb,位置請參見 0.2節。也可以在這裡找到:http://tinyurl.com/thinkdsp08
8.1 平滑化 | Smoothing
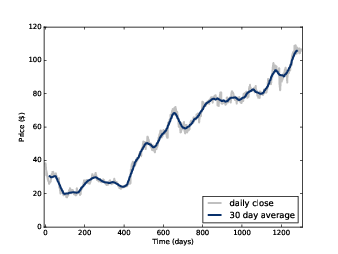
圖8.1 臉書股票每日收盤價,以及 30天移動平均。
平滑化是移除訊號中的短期波動的一種操作,它可以顯示訊號長期趨勢。舉例來說,如果你把每日股價畫成圖,你會發現它有點雜亂。對它實施平滑化的操作會讓它更容易被看出是隨時間成長或是衰退。
一個常見的平滑演算法是移動平均,它是計算前 個值的平均。
例如,圖8.1 顯示臉書每日收盤價,從 2012 年 3 月 17 到 2015 年 12 月 8 日。灰線是原始資料,深色線是 30天移動平均。平滑化移除了劇烈改變而讓它更容易看出長期趨勢。
平滑化操作也可以應用在聲音訊號。我會用一個 440 Hz 的方波做為範例,也就是在 2.2節看到的,方波的諧波會緩慢減弱,所以它含有許多高頻率的成份。
首先,我會做出該訊號與兩個波:
signal = thinkdsp.SquareSignal(freq=440)
wave = signal.make_wave(duration=1, framerate=44100)
segment = wave.segment(duration=0.01)wave 是切成一秒長度的訊號,segment 是更短的訊號,我用來畫圖用的。為了要計算這個訊號的移動平均,我會使用類似 3.7節的 window 的方法。先前我們用 Hamming window 來避免 spectral leakage (這來自於訊號開頭與結尾的不連續)。用更一般化的說法,我們可以用 window 計算波裡面某些取樣點的加權數值。
例如,要計算一個移動平均,我先建立一個 11 個元素的 window,然後把它正規化使得所有元素加總為 1。
window = np.ones(11)
window /= sum(window) ys = segment.ys
N = len(ys)
padded = thinkdsp.zero_pad(window, N)
prod = padded * ys
sum(prod)padded 是將 window 後面補零,使得其長度與 segment.ys 一樣長。像這樣補零的動作,我們叫 padding。prod 是 window 與 wave array 的乘積。兩者的元素間兩兩相乘之後再加總的結果就是 array 前 11 個元素的平均。因為這些元素都是 -1,所以平均是 -1。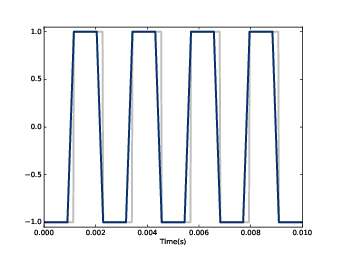
圖8.2 400 Hz 的方波訊號 (灰) 與 11-元素的移動平均
要計算下一個元素的移動平均,我們滾動(roll)這個 window,也就是裡面的 1 向右平移一格,然後把最後面的 0 移到最前面。
當我們把滾動過的 window 乘上 wave array,我們得到從 wave array 第 2 個元素開始算的 11 個元素的平均。
rolled = np.roll(rolled, 1)
prod = rolled * ys
sum(prod)我們用同樣方式計算剩下的元素。接下來的函式是將到目前為止的程式碼打包,然後放在迴圈裡,並把結果存在 array 裡。
def smooth(ys, window):
N = len(ys)
smoothed = np.zeros(N)
padded = thinkdsp.zero_pad(window, N)
rolled = padded
for i in range(N):
smoothed[i] = sum(rolled * ys)
rolled = np.roll(rolled, 1)
return smoothedsmoothed 是存放結果的 array,padded 是個 array,它擁有 window 與足夠的零使得長度為 N。rolled 是用來滾動的 padded,在迴圈裡每次向右平移一個元素。在迴圈裡,我們用
rolled 乘 ys 以選出 11 個元素然後加總。圖 8.2 顯示方波的結果,灰線是原來的訊號,深色線是平滑化的訊號。平滑訊號在 window 邊界遇到第一個訊號突起會開始陡坡上升,window 在突起上面移動時,平滑訊號也是平的。這樣的結果看來,訊號突起比較不突然,邊角也比較不尖銳。如果播放平滑訊號,它聽起來比較悶。
8.2 卷積 | Convolution
我們剛才的操作,把一個 window 疊在波上的每個小段做計算,叫做卷積 convolutino。卷積是一個很常見的操作,numpy 提供了更簡單也更快速的版本。
convolved = np.convolve(ys, window, mode='valid')
smooth2 = thinkdsp.Wave(convolved, framerate=wave.framerate)np.convolve 計算了 wave array 與 window 的卷積。valid 這個模式是說只計算 wave array 與 window 完整重疊的數值。所以,當 window 右邊碰到 wave array 最右邊時就會停止計算。除此之外,其結果與圖 8.2 相同。實際上還有一個不同。前一節計算的實際是 cross-correlation:
是 wave array,其長度為 , 是 window,是 cross-correlation 的符號。要計算結果的第 n 個元素,我們移動 到右邊,也就是為什麼索引是 。
卷積的定義有一點點不一樣:
譯註:從維基百科的網頁看,cross-correlation 的符號是五角星星,convolution 的符號是米字星星。在 latex 中,五角星星是 star,米字星星是 ast (asterisk)。
是卷積的符號。兩者的差異在於 的索引 ,它是負的,所以對 的列舉(iterate)是反向的,也就是從 array 的尾端向前。
因為我們在範例中的 window 是對稱的,所以 cross-correlation 與卷積的結果會一樣。當我們用其他的 window 時,就要小心這個差異。
你也許會好奇,為什麼卷積要這樣定義,讓 window 是倒過來用。這有兩個理由:
- 這定義來自其他數個的應用,特別是訊號處理的分析。是第十章的主題。
- 這定義是卷積理論的基本,等下就介紹。
8.3 頻域 | The frequency domain
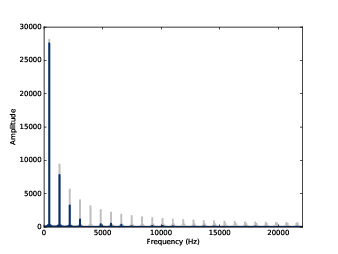
圖8.3 平滑化前後的方波頻譜
平滑化讓方波訊號比較不突然,讓聲音有一些些悶。來看看在頻譜上有什麼影響。首先,先畫上原來的波:
spectrum = wave.make_spectrum()
spectrum.plot(color=GRAY) convolved = np.convolve(wave.ys, window, mode='same')
smooth = thinkdsp.Wave(convolved, framerate=wave.framerate)
spectrum2 = smooth.make_spectrum()
spectrum2.plot()same 的模式是要讓輸出跟輸入一樣的長度。在這個範例中,它會指定一些數值包覆輸入。圖8.3 是其結果。基頻幾乎沒變,前幾個諧波有被抑制,較高頻諧波幾乎被消除。所以平滑化有低通濾波器的效果,我們在 1.5節與 4.4節看過。
要看每個成份被抑制多少,我們可以計算兩個頻譜的比例:
amps = spectrum.amps
amps2 = spectrum2.amps
ratio = amps2 / amps
ratio[amps<560] = 0
thinkplot.plot(ratio)ratio 是平滑化前後的指幅的比例。當 amps 小的時候,這比例就會很大,造成圖很雜亂,所以為了簡化,在不是諧波的地方,我都把比例弄成 0。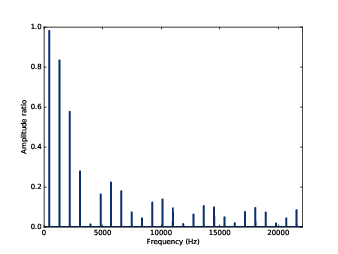
圖 8.4 平滑化前後的方波頻譜的比例圖
圖 8.4 顯示其結果。如預期,對低頻來說,比例是高的,大約超過 4000 Hz 之後就下降。但有我們沒預期的事,為什麼下降的比例會在 0 到 0.2 之間,發生什麼事?
8.4 卷積理論 | The Convolution Theorem

圖 8.5 平滑化前後的方波頻譜的比例圖,在加上平滑 window 的 DFT
答案是卷積理論。用數學方式表示是:
是 wave array, 是 window。換成人話是,卷積理論說,如果我們將 與 做卷積,然後計算它的 DFT,它的結果會等於先計算 與 的 DFT,再對兩個做元素間乘法。
當我們對一個波做類似卷積的操作,我們會說我們在 時間領域 time domain 做操作,因為波是時間的函數。當我們對 DFT 做類似乘法的操作,我們是在 頻率領域 frequency domain 做操作,因為 DFT 是頻率的函數。
使用這些術語,我們可以更簡潔地表述卷積理論:
卷積在時間領域對應到頻率領域的乘法這就解釋圖8.4,因為當我們對一個波與 window 做卷積,我們是用波的頻譜乘上 window 的頻譜。要了解它怎麼做到的,我們可以計算 window 的 DFT。
padded = zero_pad(window, N)
dft_window = np.fft.rfft(padded)
thinkplot.plot(abs(dft_window))padded 包含了平滑 window,用零補長度與 wave 同長度。dft_window 包含 padded 的 DFT。圖8.5 顯示其結果,也加上前一節計算的比例,這些比例正好是
dft_window 的振幅。用數學表示:在這樣的脈絡下,window 的 DFT 叫做 filter (濾波器)。對任何在時間領域的卷積 window,在頻率領域都對應一個濾波器。對於任何濾波器,只要它可以在頻率領域表示成元素間乘法,都會有一個對應的 window。
8.5 高斯濾波器 | Gaussian filter
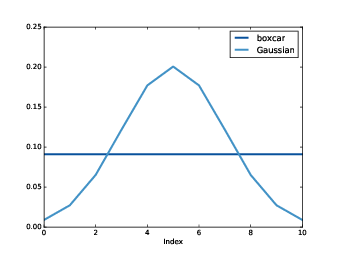
圖8.6 箱車與高斯 window
我們前一節使用的移動平均 window 是個低通濾波器,但他不是非常好。DFT 一開始下降快速,然後又彈起,這些彈起叫做
sidelobe 旁瓣。這是因為移動平均 window 長像方波,所以它的頻譜裡面的高頻諧波下降正比於 ,這相對慢。我們用高斯濾波器會更好,scipy 提供許多計算常用的卷積 window 的函式,也包含
gaussian: gaussian = scipy.signal.gaussian(M=11, std=2)
gaussian /= sum(gaussian)M 是 window 有幾個元素,std 是高斯分佈的標準差。圖8.6 顯示 window 的形狀。它是離散近似高斯鐘形分佈。這圖也顯示前一節移動平均,這通常叫做箱車,因為它看來像是長方形鐵道車箱。
圖8.7 頻譜的比例,在高斯平滑化前後,以及 window 的 DFT
我用這個 window 重新計算前一節的例子,產生圖8.7,它顯示在平滑化前後的頻譜的比例,以及高斯 window 的 DFT。
以低通濾波器來說,高斯平滑表現比簡單移動平均。在比例下降之後,它保持低值,而且幾乎沒有旁瓣。所以它在切斷高頻的工作做得更好。
它效果好的原因是高斯曲線的 DFT 也是高斯曲線,所以比例下降正比於 ,它比 更快。
8.6 有效率的卷積 | Efficient convolution
FFT 如此重要的原因之一,當它當合卷積理論時,它提供一個有效率的方法計算卷積、cross-correlation 與 autocorrelation。再看一下卷積理論是說:
所以一個計算卷積的方法是:
其中 是 inverse DFT。卷積的簡單實作的執行時間會正比於 。這個演算法,它使用 FFT 則會是正比於 。
要驗證它是否正確,我們用兩個方式計算同一個卷積。我拿圖8.1 裡臉書的資料來當例子。
import pandas as pd
names = ['date', 'open', 'high', 'low', 'close', 'volume']
df = pd.read_csv('fb.csv', header=0, names=names)
ys = df.close.values[::-1]其結果
df 是個 DataFrame,它是 pandas 提供的資料結構之一。close 是 numpy array,它包含每日收盤價。接下來,我建立一個高斯 window,讓它跟
close 做卷積: window = scipy.signal.gaussian(M=30, std=6)
window /= window.sum()
smoothed = np.convolve(ys, window, mode='valid')fft_convolve 則是用 FFT 做相同的事:from np.fft import fft, ifft
def fft_convolve(signal, window):
fft_signal = fft(signal)
fft_window = fft(window)
return ifft(fft_signal * fft_window)ys 同長度,然後計算卷積: padded = zero_pad(window, N)
smoothed2 = fft_convolve(ys, padded) M = len(window)
smoothed2 = smoothed2[M-1:]8.8 有效率的自相關 | Efficient autocorrelation
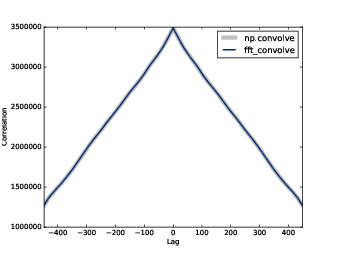
圖8.8 用 numpy 與 fft_correlate 計算的自相關函數
8.2節,我們介紹了 cross-correlation 與卷積的定義。我們知道它們兩個幾乎一樣,只是卷積的 window 是反過來的。
現在,我們有一個卷積的快速演算法,我們可以用它來計算 cross-correlation 與自相關。使用前一節的資料,我們計算臉書股價的自相關:
corrs = np.correlate(close, close, mode='same')close 一樣,對應的延遲會是 到 。圖8.8 的灰線就是結果。除了 lag=0,它在那裡沒有尖峰,所以在這訊號裡沒有明顯週期行為。然後,自相關下降緩慢,意味這訊號由粉紅噪音組成,如同之前 5.3節所見。用卷積計算自相關,我們必須把訊號用零補齊,長度是兩倍。這技巧之所以需要是因為 FFT 是建立在訊號是週期的假設上。也就是,將它從尾巴再繞回開頭。使用像這樣的時間序列的資料,這假設是無效的。因此加上零,計算完然後切去零值,移去假的值。
還有,卷積的 window 是反向的,為了要消取這個效應,我們在呼叫
fft_convolve 前先把 window 反過來,也就是先呼叫 np.flipud,它會把 numpy array 反過來,得到的結果是 array 的視圖,而不是副本,所以操作比較快。def fft_autocorr(signal):
N = len(signal)
signal = thinkdsp.zero_pad(signal, 2*N)
window = np.flipud(signal)
corrs = fft_convolve(signal, window)
corrs = np.roll(corrs, N//2+1)[:N]
return corrsfft_convolve 算出的結果是 ,前後 的值是有效的。剩下的是補零的結果。要選擇有效元素,我們滾動這些結果且選擇前 個,對應到延遲 到 如果圖8.8 顯示,由 fft_autocorr 與 np.correlate 計算的結果相同(約有 9 位數的準確度)。
要注意圖8.8 的相關其數字比較大,我們可以將其正規化(壓到 -1 與 1 之間),如同 5.6節。
我們這裡對自相關用的策略,也能用在 cross-correlation。同樣,必須要把訊號反向與補齊,然後必須去掉結果裡無效的部份。這個補齊與去除的動作是個累贅,所以像 numpy 之類的函式庫都會提供函式。
8.8 練習
Solutions to these exercises are in chap08soln.ipynb.Exercise 1 The notebook for this chapter is chap08.ipynb. Read through it and run the code.
It contains an interactive widget that lets you experiment with the parameters of the Gaussian window to see what effect they have on the cutoff frequency.
What goes wrong when you increase the width of the Gaussian, std, without increasing the number of elements in the window, M?
Exercise 2 In this chapter I claimed that the Fourier transform of a Gaussian curve is also a Gaussian curve. For Discrete Fourier Transforms, this relationship is approximately true.
Try it out for a few examples. What happens to the Fourier transform as you vary std?
Exercise 3 If you did the exercises in Chapter 3, you saw the effect of the Hamming window, and some of the other windows provided by NumPy, on spectral leakage. We can get some insight into the effect of these windows by looking at their DFTs.
In addition to the Gaussian window we used in this chapter, create a Hamming window with the same size. Zero-pad the windows and plot their DFTs. Which window acts as a better low-pass filter? You might find it useful to plot the DFTs on a log-y scale.
Experiment with a few different windows and a few different sizes.


為了要計算這個訊號的移動平赱 -> 均
回覆刪除3Q
刪除